|
1 �vʷ
����������r�������IT�ИI���~�R���S֮�����Ĕ����}�졢������ȫ�����������������ھ�ȵȇ��@�����̘I�rֵ��������u�ɞ��ИI��ʿ���������������c��
���ڡ�������Big
data���о��C��Gartner�o�����@�ӵĶ��x������������Ҫ��̎��ģʽ���ܾ��и����ěQ����������l�F�������̃��������ĺ����������L�ʺͶ��ӻ�����Ϣ�Y�a��
�������@���g�Z�����ڵ����ÿ��ݵ�apache org���_Դ�ĿNutch�����r�����Á���������¾W�j����������Ҫͬ�r�M������̎��������Ĵ������������S���ȸ�MapReduce��Google
File System ��GFS���İl���������كH�Á����������Ĕ�����߀���w��̎�픵�����ٶȡ�
����1980�꣬����δ��W�Ұ����ġ��з��ձ��ڡ��������˳���һ���У����������ٝ힞顰�������˳����A�ʘ��¡������^����s��2009���_ʼ����163�����ųɞ黥�W��Ϣ���g�ИI�������~�R���������W��������ָ�������W�ϵĔ���ÿ�ꌢ���L50%��ÿ����㌢��һ������Ŀǰ������90%���ϵĔ������������Ůa���ġ����⣬�����ֲ��džμ�ָ�˂��ڻ��W�ϰl������Ϣ��ȫ����Ĺ��I�O�䡢��܇��늱��������o���Ĕ��a���������S�r�y���͂��f�����Pλ�á��\�ӡ����ӡ��ضȡ���������՚��л��W���|��׃����Ҳ�a���˺����Ĕ�����Ϣ�� ���ߌ��I�W���
2 ԭ��
�����g�đ������x��������������Ĕ�����Ϣ�������ڌ��@Щ�������x�Ĕ����M�Ќ��I��̎�����Q��֮������Ѵ�����һ�N�a�I����ô�@�N�a�I���Fӯ�����P�I��������ߌ������ġ��ӹ���������ͨ�^���ӹ������F�����ġ���ֵ����
�ļ��g�Ͽ���
���c��Ӌ����Pϵ
���c��Ӌ����Pϵ����һöӲ�ŵ�������һ���ܲ��ɷ֡�����Ȼ�o���Æ��_��Ӌ��C�M��̎������횲��÷ֲ�ʽ�ܘ���������ɫ���ڌ����������M�зֲ�ʽ�����ھ�SaaS�����������������Ӌ��ķֲ�ʽ̎�����ֲ�ʽ�����죨PaaS�����ƴ惦��̓�M�����g��IaaS�����S���ƕr���ā��R������Big
data��Ҳ������Խ��Խ����Pע���������_���ķ������F��J�飬����Big
data��ͨ���Á�����һ����˾����Ĵ����ǽY���������Ͱ�Y�����������@Щ���������d���Pϵ�͔��������ڷ����r�����M�^���r�g�ͽ��X��������������Ӌ��ϵ��һ����錍�r�Ĵ��͔�����������Ҫ��MapReduceһ�ӵĿ�܁���ʮ�����ٻ�������ǧ����X���乤��������Ҫ����ļ��g������Ч��̎�����������̽��^�r�g�ȵĔ������m���ڴ��ļ��g��������Ҏģ����̎����MPP�������졢�����ھ�늾W���ֲ�ʽ�ļ�ϵ�y���ֲ�ʽ�����졢��Ӌ��ƽ�_�����W�ͿɔUչ�Ĵ惦ϵ�y��
��С�Ļ�����λ��Byte�������o�����І�λ��bit��Byte��KB��MB��GB��TB��PB��EB��ZB��YB��BB��NB��DB��
���������M��1024��2��ʮ�η�����Ӌ�㣺
1Byte = 8 bit
1 KB = 1,024 Bytes
1 MB = 1,024 KB = 1,048,576 Bytes
1 GB = 1,024 MB = 1,048,576 KB
1 TB = 1,024 GB = 1,048,576 MB
1 PB = 1,024 TB = 1,048,576 GB
1 EB = 1,024 PB = 1,048,576 TB
1 ZB = 1,024 EB = 1,048,576 PB
1 YB = 1,024 ZB = 1,048,576 EB
1 BB = 1,024 YB = 1,048,576 ZB
1 NB = 1,024 BB = 1,048,576 YB
1 DB = 1,024 NB = 1,048,576 BB |
|
3 �☋
�����ǻ��W�lչ���F���A�ε�һ�N������������ѣ��]�б�Ҫ��Ԓ���������־�η֮�ģ�������Ӌ�������ļ��g���´�Ļ���r���£��@Щԭ�����y�ռ���ʹ�õĔ����_ʼ���ױ����������ˣ�ͨ�^���и��I�IJ������£���������������ărֵ��
��Σ���Ҫϵ�y���J֪�������Ҫȫ������µķֽ����������֏����������չ�_��
��һ��������Փ����Փ���J֪�ıؽ�;����Ҳ�DZ��V���Jͬ�͂����Ļ������ҕ��Ĵ����������x�����ИI���������w���L�Ͷ��ԣ��Č����rֵ��̽ӑ����������������F���ڣ���Ϥ���İlչڅ�ݣ��Ĵ��[˽�@���e����Ҫ��ҕ�nj�ҕ�˺͔���֮�g���L�ò��ġ�
�ڶ������Ǽ��g�����g�Ǵ��rֵ�w�F���ֶκ�ǰ�M�Ļ�ʯ���Ҍ��քe����Ӌ�㡢�ֲ�ʽ̎�����g���惦���g��֪���g�İlչ���f�����IJɼ���̎�����惦���γɽY���������^�̡�
���������nj��`�����`�Ǵ�����K�rֵ�w�F���Ҍ��քe�Ļ��W�Ĵ��������Ĵ�����I�Ĵ��͂��˵Ĵ��Ă���������L���ѽ�չ�F�����þ��������F���{�D�� ���ߌ��I�W���
4 ���c
����������ڂ��y�Ĕ����}�쑪�ã����Д�������ԃ�������s�����c����Ӌ��C�W���ǵġ��ܘ��������𡢬F���cչ����һ�����e�˴�����ƽ�_��Ҫ�߂�Ďׂ���Ҫ���ԣ�����ǰ���������Fƽ�_�������Д����졢MapReduce�����ڃ��ߵĻ�ϼܘ��M���˷����w�{��ָ���˸��Եă��ݼ����㣬ͬ�rҲ������������о��F������ڴ����������Ŭ���M���˽�B����δ���о�����չ����
����4����V���������f���c���Ă����棺��һ�������w����TB���e���S����PB���e���ڶ���������ͷ��ࡣǰ���ᵽ�ľW�j��־��ҕ�l���DƬ������λ����Ϣ�ȵȡ������������ā�Դ��ֱ�ӌ��·����Y���Ĝʴ_�Ժ��挍�ԡ���������Դ�������IJ����挍����K�ķ����Y���Լ��Q�������Ӝʴ_�����ģ�̎���ٶȿ죬1�붨�ɡ�����@һ�cҲ�Ǻ͂��y�Ĕ����ھ��g�������|�IJ�ͬ���I�猢��w�{��4����V������Volume����������Velocity�����٣���Variety�����ӣ���Veracity���挍�ԣ�
��ij�N�̶����f�����ǔ���������ǰ�ؼ��g������֮���ĸ��N������͵Ĕ����У����٫@���Ѓrֵ��Ϣ�����������Ǵ����g�������@һ�c���P��Ҫ��Ҳ�����@һ�c��ʹԓ���g�߂�������I�ĝ�����
5 ��;
���ɷֳɴ����g�������̡����ƌW�ʹ����õ��I��Ŀǰ�˂�ՄՓ�����Ǵ����g�ʹ����á����̺ͿƌW���}��δ����ҕ��������ָ����Ҏ�����O�\�I������ϵ�y���̣����ƌW�Pע���W�j�lչ���\�I�^���аl�F����C����Ҏ�ɼ����c��Ȼ��������֮�g���Pϵ��
���W����Ӌ�㡢�Ƅӻ��W��܇�W���֙C��ƽ����X��PC�Լ��鲼�����������ĸ��N���ӵĂ��������oһ���ǔ�����Դ���߳��d�ķ�ʽ��
��Щ���Ӱ����W�j��־��RFID���������W�j������W�j��������������ڔ�������������������W�ı����ļ�;���W��������;����Ԕ��ӛ䛣����ČW�����ƌW������M�W��������W��������������s��/���W�ƵĿ��У�܊�ɲ죬�t��ӛ�;�zӰ�n���^ҕ�l�n��;�ʹ�Ҏģ������̄ա� ���ߌ��I�W���
6 ����
��ɼ������ֺͼ������၆��W�������ô��A�y����İl����
google����څ��(Google Flu Trends)���������P�I�~�A�y�����е�ɢ����
�yӋ�W�҃���.������(Nate Silver)���ô��A�y2012�����x�e�Y����
��ʡ�����WԺ�����֙C��λ�����ͽ�ͨ������������Ҏ����
÷����؛�Č��r���r�C�ơ���������͎�����r��ԓ��˾����SAS��ϵ�y�����_7300�f�N؛Ʒ�M�Ќ��r�{�r��
Tipp24 AGᘌ��W���ʘI��������ע���A�yƽ�_��ԓ��˾��KXENܛ����������ʮ�|Ӌ�Ľ����Լ��͑������ԣ�Ȼ��ͨ�^�A�yģ�͌��ض��Ñ��M�ЄӑB�ĠI�N��ӡ��@��e��p����90%���A�yģ�͘����r�g��SAP��˾����ԇ�D��ُKXEN����SAP��ͨ�^�@����ُ��Ť�D���L���ԁ����A�y����������ӄݡ���Laney��������
�֠������������@�����ۘI���^����Wվ�����OӋ�����µ���������Polaris�������Z�x�����M���ı��������C���W����ͬ�x�~�ھ�ȡ������֠������f�����Z�x�������g���\��ʹ���ھ�ُ��������������10%��15%�������֠������f���@����ζ����ʮ�|��Ԫ�Ľ��~����Laney�f����͘I��ҕ�l����(Laney�]���f���@�ҹ�˾������)��ԓ��˾ͨ�^ҕ�l�����Ⱥ���е��L�ȣ�Ȼ���Ԅ�׃����Ӳˆ��@ʾ�ă��ݡ��������^�L���t�@ʾ���Կ��ٹ��o��ʳ��;�������^�̣��t�@ʾ��Щ�����^�ߵ��ʂ�r�g�����L��ʳƷ��
Mortonţ�ŵ��Ʒ���J֪����һλ��_��Ц��ͨ�^�������@��λ��֥�Ӹ��ţ���B�i��ӆ���͵��~�sNewark�C��(������һ�칤��֮����_ԓ̎)�r��Morton���_ʼ���Լ����罻�㡣���ȣ��������ؔ������l�Fԓ��DZ���ij��ͣ�Ҳ�����صij����ߡ������͑�������ӆ�Σ��Ɯy�������˵ĺ��࣬Ȼ���ɳ�һλ������β�������ߞ�͑��ṩ���͡�Ҳ�S���@ �����^���x�棬�������회�ҕ�Լ��������Ƿ������������@���̶�?��Laney�f��
PredPol Inc.��PredPol��˾ͨ�^�c��ɼ����ʥ����˹�ľ����Լ�һȺ�о��ˆT���������ڵ����A�y�㷨��׃�w�ͷ�������A�y����l���Ď��ʣ����Ծ��_��500ƽ��Ӣ�ߵķ����ȡ�����ɼ���\��ԓ�㷨�ĵ^���I�`��ͱ�������ֲ��½���33%��21%��
Tesco
PLC(����ُ)���\�IЧ�ʡ��@�ҳ����B�i���䔵���}�����ռ���700�f������Ĕ�����ͨ�^���@Щ�����ķ������M�и�ȫ��ıO�ز��M�����ӵľS���Խ������w�ܺġ�
American
Express(�����\ͨ��AmEx)���̘I���ܡ�������AmExֻ�܌��F�º��T��ʽ�Ĉ��͜�����A�y�������y��BI�ѽ��o���M��I�հlչ����Ҫ����Laney�J�顣���ǣ�AmEx�_ʼ���������܉��A�y���\�ȵ�ģ�ͣ����ښvʷ���ה�������115��׃�����M�з����A�y��ԓ��˾��ʾ�����ڰĴ���������֮���Ă�������ʧ�Ŀ͑����ѽ��܉��R�e�����е�24%��
Express Scripts Holding
Co.�ĮaƷ���졣ԓ��˾�l�F��Щ��Ҫ��ˎ���˳���Ҳ���������ӛ��ˎ���ˡ���ˣ������_�l��һ���®aƷ�����⏵�ˎƷ�w���Ԅӵ��Ԓ���У��Դ����ѻ��߰��r��ˎ��
Infinity Property & Casualty Corp.�ĺڰ�����(dark data)��Laney���ںڰ������Ķ��x�ǣ���Щᘌ���һĿ�˶��ռ��Ĕ�����ͨ�����^֮��ͱ��w�n�e�ã��������rֵδ�ܱ�����ھ����ض���r�£��@Щ������������������;��ԓ��˾���۷e�����r�������������p������ͨ�^�㷨�����1200�f��Ԫ�Ĵ�λ�����~�� ���ߌ��I�W���
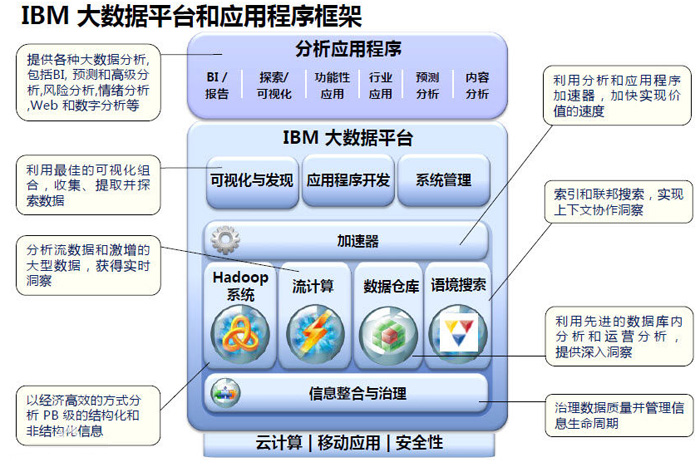
IBM����
IBM�Ĵ�����������2012��5�°l���ǻ۷������조3A5�����ӑB·���D������A�����^��3A5������ָ�����ڡ�������Ϣ����Align���Ļ��A�ϡ��@ȡ���족��Anticipate�����M����ȡ�Єӣ�Act���������Q�߲߄��܉�ȘI�տ�Ч������֮�⣬߀��Ҫ����ء��W������Learn����ÿһ�ΘI�սY���Ы@�÷��������ƻ�����Ϣ�ěQ�����̣��Ķ����F���D�͡���Transform����
���ڡ�3A5�����ӑB·���D��IBM����ˡ���ƽ�_���ܘ���ԓƽ�_���Ĵ������������Hadoopϵ�y����Ӌ�㣨StreamComputing���������}�죨Data
Warehouse������Ϣ�����c������Information Integration and Governance����
�ڴ�̎���I��IBM��2012��10���Ƴ���IBMPureSystems���Ҽ���ϵ�y���³ɆT����IBM PureDataϵ�y���@��IBM�ڔ���̎���I��l�����ׂ�����ϵ�y�aƷϵ�С�PureDataϵ�y���w��������aƷ���քe��PureDataSystem
for Transactions��PureData System forAnalytics��PureData System for
Operational Analytics���ɷքe������OLTP���C��̎������OLAP���C����̎�����ʹ������������c��ǰ�l����IBMPureSystemsϵ�ЮaƷһ�ӣ�IBM
PureDataϵ�y�ṩ���õČ��I֪�R��Դ���OӋ�ļ��ɣ��Լ������������������еĺ����w
˹¡����Ѳ���ռ���������Ďׂ����ڣ��ͱ������ČW�Ěvʷ��ֵ�X��2000����ռ��˸���Ĕ��������Ǖr�ԁ������ѽ��e����140�����ֹ�����Ϣ���@�����h�R���^���ߣ������Ѳ�����h�R������2016���ھW�ό��@�Ô����������֠���ÿ��һС�r̎�����^100�f�͑��Ľ��ף�������������Ӌ���^2.5
PB�ஔ�����������D���^�ĕ�����167��
��FACEBOOK�������Ñ�Ⱥ�@�ò�̎��400�|����Ƭ����a��ԭʼ�������M���M10��r�g̎������������һ�����ڃȌ��F��
��������Ӱ푣������ˌ���Ϣ���팣�ҵ������ģ�IBM��ܛ��SAP���˳��^15�|��Ԫ����ܛ�����ܔ��������ͷ����Č��I��˾���@���ИI����rֵ���^1000�|��Ԫ�����L��10%��ÿ��ɴΣ��@���������һ�����w��ܛ���I�յĿ��١�
���ѽ����F������҂�������һ���и�����Ϣ������С���46�|ȫ���Ƅ��Ԓ�Ñ���20�|���L�����W�������ϣ��˂��������κΕr���c��������Ϣ������
1990����2005�꣬ȫ���^1�|���M���Юa�A�����@��ζ��Խ��Խ�����������@�P�X�����^�팧�¸������Ϣ���L��˼�ƹ�˾�AӋ����2013�꣬�ڻ��W�����ӵĽ�ͨ�����_��ÿ��667���ֹ���
������Ӱ푳��˽�������ģ���ͬ�rҲ�������Ρ��Ļ��ȷ���a�����h��Ӱ푣������Ԏ����˂��_��ѭ������������ģʽ��Ҳ���҂����¡���������ļ����w�F�����ּ��g���߷֔������Ô����ߵ����¡�
7 �����rֵ
������֪����I�����������N�����rֵ�����nj����õĔ����c�]�Ѓrֵ�Ĕ����M�Ѕ^�ֿ�����������һ�����ֵĆ��}��
�@Ȼ���������յ��ˆT��r�����Y���Ϳ͑�ӛ䛌�����I���\�D���P��Ҫ��������������Ҳ�����D����rֵ��������һ��ӛ��˂�����������̵�g�[ُ���ҕ�l���˂���ُ�I���ķ���ǰ����������顢���ͨ�^�罻�W�jϵ���Ŀ͑�����ʲô�������������ˡ��͑���θ����Լ�������ϲ�g���տʽ���������@Щ�������ṩ�˺ܶ�ָ��������z���O���^��������R�^�죬�����c�������������գ��������c����ͬ�ķ�ʽ�������ʣ������������·�ʽ�l���췭�ظ����D׃�� ���ߌ��I�W���
���nj�Ҋ���r���ǣ��ܶ˾��Ȼֻ�nj���Ϣ���ζ���һ�𣬃H���䮔����M�㹫˾����Ҏ�t�����Ҫ�������Ϣ����̎���������nj�������������D׃�Ĺ��ߡ�
�������������ˆT�ǘI�ղ��T�H�еăɹP�o�����������֏��Ƶ�ؔ���������õ������У��õĔ��������й���Q�ߵĻ��A���������nj��͑��������˽�������ݡ������ǘI�ղ��T������������������ڛQ�ߺ��Єӕr�o�p�Ұ�ȫ�������˂����С�
���ԣ�������ԓ�S�r��Q���ṩ�������������������_��·������ͨ��ʹ����Ϣ�@�ӿ������������c�ޝ��Ĕ����r���l��ʲô���@Щ������Դ��һЩ˽�I��˾�ṩ�˾�ărֵ���@Щ��˾�܉������@Щ����������M�㝓��������®aƷ�ͷ��ա�
��I��Ҫ�����ȡ�Ô��������Ͷ����ȡ�؈���Ч����������f��Դ�Ĕ����Լ��@ȡ�܉��ƽ����������x�Ĺ���ֻ�ǵ�ʽ��һ���֣������@�N�����ݵ����a���Ĕ����ڔ����ϳ��m��Û�����l��ҕ�l�͈D��ȸ�ý�w��Ҫ�µķ������l�F������]����IM��tweet���罻�W�j�Ⱥ����ͽ���ϵ�y�ԷǽY�����ı�����ʽ���攵���������һ�N���ܵķ�ʽ�����x��
���ǣ���ԓ���@�N���s�Կ�����һ�N�C�������dž��}��̎���������_�r���a���Ĕ���Խ�࣬�Y���͕�Խ����ɿ�����������GPSϵ�y���罻�����������猢�����D׃�\�I���@����ҕ�Ǻ͙C����Ո��Ҫ�e�^��
��Щ�˕��f���������N���ărֵֻ���Ɍ��I�ˆT�����x�����ǝ��ֹ���������ֻ�ǔ����ƌW�Һ��_�l�T�����¡�
�����ărֵ���ڌ����_����Ϣ�����_�ĕr�g���������_�������С�δ�팢������Щ�܉��{�S�����Д����Ĺ�˾���@Щ�����c��˾�����ĘI�պͿ͑����P��ͨ�^�����������ã��l�F�µĶ�Ҋ�����������ҳ��������ݡ�
8 �����C��
�ԏ�����IT���T��������һֱ��Ҫ����Ϣ���팣���ṩ�����������H�ϣ�����1951�꣬���A�yС�Ե군��������V��ʹ�����Ӌ��C���״��̘I���á������Ժ��҂����ü��g���R�eڅ�ݺ��ƶ����ԑ��g�����������ָ�����������ơ�
���죬�̘I���� (ʹ�Ô���ģʽ���������܇���һ��) ���� CXO ��������֮�ء�������������У�IT
�Ǿ�ĸܗU����׃�˹�˾��Ӱ������������������ʡ���X�������������䐂�I�ҡ����p���\�Ñ��������ڿ͑��D����͑����������������������֡��_���Ñ�Ⱥ�������Ј���
���������̘I���ܵ����M������������GPS ϵ�y��QR
�a���罻�W�j�����ڄ����µĔ������������@Щ�����Եõ��l�������@�N�����V�Ⱥ���ȵ���Ϣ�ڄ��첻��ö�e�ęC����Ҫʹ����֮����Ա�����С��I����ͨ�^�����N���͑��ķ�ʽȡ�ø������ݣ��������ɺ͔��������Ǻ������ڡ�
���R��ȫ��˥�����{���L���� IT ���T�I����Ҫ�ھ����д��^ꇣ��½����h���е��A�Ҍ�������õ�������Щָ��Ӱ����ǰ�M���ˡ�
��Ȼ����I�Ԍ���Ҫ�����ˆT������ǵěQ�ߣ��˽��������R��ʲô���ڳ�����õ���r�£��������x���˂��������й�֪�X��������Charles
Duigg�ǡ����T��������һ�������ߣ����ҳ���һ���S��������������������������
Target����l�F�DŮ�ڑ��е����g����������ُ�I�]�К�ζ���o�wҺ��ijЩ�S���ء�ͨ�^�i���@Щُ���ߣ��̵���ṩ���@Щ�DŮ׃�����\�͑��ă���ȯ�����H�ϣ�Target
֪��һλ�DŮ���Еr����λ�DŮ����߀�]�и��V���H�����H����� -- ����Ҫ�f�̵��Լ��ˡ�
�����@���ڿ����AҊ�Č������[˽��������Ҫ�Ŀ��������ǚw���Y�ף������˽��О�ļ��g���鷽�����控���p�A���u���˽��I�ң��I��ϲ�g�I���Ė|����
�ٿ�һ�����Ҽ�ƌW�� Stephen Wolfram�����ӣ����ռ����P�������T�Ĕ������Է������Ă����О飬�A�y�¼���δ���Ŀ����ԡ�
�������Ŵ��҂����������˽⿴�����y��������S�C���������ǰ;���˽��ṩ�˫@ȡ����֪�R�������ęC��������׃������I�\���ķ�ʽ��
9 �����؈�
������֮����I����ͨ�^˼���������ԵĿ��w�؈푪����������ץס���ęC����Informatica��ָ�ġ������؈��ʡ����Ǟ������IT�͘I�ղ��T�I�����M�д������đ��g�͑��Ժ��x��ӑՓ���OӋ��һ�����θ����ʽ�dz����Σ��������ߔ������ژI�ղ��T�ărֵ��ͬ�r�����픵���ijɱ����Ĕ����õ��Ļ؈�͕�����
-- �oՓ���ý��X������߀�Ǹ��õěQ��
�����؈���=�����rֵ/�����ɱ�
�ڼ��g���棬�����؈��ʞ锵�����ɡ������������̘I���ܺͷ��������Ͷ���ṩ�˘I�ձ����Ͱ�������߀�c��Q�I�յĻ��A���P�����X��ʡ�X������C�������L�U�����漰��Ч�ʵĿ��]��ͬ�r�Ƅ��˸�׃�Α�Ҏ�t�Ķ�������
10 ���F�؈�
Informatica��֪�����ںܶ���I���f�����؈�ģ�͵��D׃����һ�����͡����픵��������ɱ����͵Ķ���Ҫ������Ҫ���c��ͬ��߀��Ҫ�����ϵK���˽┵������Iֻ���@�r�ſ����_ʼ�Ă��y�����d�������@�ø����rֵ��Informatica���ṩ��������ƽ�_���I����������I�ṩȫ�̎�����
�ڴ��������У����`��ͳɹ�����I��������Щ���ô�C���Ĺ�˾��
11 ̎������
��ǰ���ڷ������Ĺ�����Ҫ���_Դ�c���Ãɂ����BȦ��
�_Դ�����BȦ��
1��Hadoop HDFS��HadoopMapReduce, HBase��Hive �u���Q��������Hadoop���BȦ���γɡ�
2��. Hypertable�������������Hadoop���BȦ֮�⣬��Ҳ������һЩ�Ñ���
3��NoSQL��membase��MongoDb
���ô����BȦ��
1��һ�w�C������/�����}�죺IBM PureData(Netezza), OracleExadata, SAP Hana�ȵȡ�
2�������}�죺TeradataAsterData, EMC GreenPlum, HPVertica �ȵȡ�
3���������У�QlikView�� Tableau �� �Լ����ȵ�Yonghong Data Mart ��
12 ��������
SOAģ��
�҂���Ҫ�����Ԕ��������ĵ�SOA߀����SOA�����ĵĔ�����
SOA����ģ��
��ȡ�Q�����̎����SOA-�����Pϵ��������ͬģ�́����������Ɣ����͔����ӴνY������Խ��Խ���̓�M�YԴ�У����@Щģ��֮�g������͵Ĕ����M����M����SOA�����R�ľ�����֮һ������Ԕ����B��ÿ��SOAģ���픵���ă��c���x����x헡�
SOA��������������ģ�ͷքe�ǔ���������(DaaS)ģ�͡�����ӴνY��ģ�ͺͼܘ��M��ģ�͡�DaaS������ȡ��ģ�������˔���������ṩ�oSOA�M���ġ�����ģ�������˔�������δ惦���Լ��惦�ČӴΈD������͵�SOA�����惦���ϵġ���ܘ�ģ�������˔����������������պ�SOA�M��֮�g���Pϵ��
SOA�͔�����I������
Ҳ�S�ԘO����r���_ʼ������SOA�������}����÷�ʽ��һ����I�Ĕ���������ȫ�������Pϵ���������ϵ�y(RDBMS)�еėl�����ʾ���@��һ����I���ܕ�ֱ�Ӳ��Ô������O����ߌ����õĔ�����������ͬF�еIJ�ԃ�����B�ӵ�SOA�M������ԃ�����գ���QaaS���ϡ��@�N�OӋ����֮ǰ�ѽ����˂������ܡ�ԓ�OӋ֮���Գɹ��������ƽ������������ģ��֮�g���Pϵ��QaaS����ģ�Ͳ��ǙCе���B�ӵ��惦���ϣ�����ͨ�^һ����һ�ļܘ�����
RDBMS���Pϵ�͔��������ϵ�y��������ȥ�غ������Ա��ڹ����һ�ļܘ���
ͨ�^�������ӿ��Ը��õ������ʲô�@�����εķ����s�����ڸ���ķ�����̎�픵���������Ĵ��Ƿ��Pϵ�͵ġ��ǽ����͵ġ��ǽY������������δ���µĔ���������ȱ�������Y����ˌ�������һ����ԃ���ղ������£����ڔ����ж�����Դ����ʽ��˺��ٰ���惦�����Ҷ��x���A�����������Ժ�ȥ���^������һЩҎ�t�ġ�����������뵽SOA�đ��ó����Еr���P�I��Ҫ���x���Nģ���е����һ�Nģ�ͣ�SOA�����Pϵ�еļܘ�ģ�͡��ЃɷN�x��ˮƽ����ʹ�ֱ����
SOA�����ģ��
��ˮƽ���ɔ���ģ���У������ռ��[����һ�׳���Ĕ�����������ԓ��������һ��������ӿ��B�ӵ����ó����ϣ�Ҳ�ṩ���е������Ժ͔����������ܡ��M���m����ֱ���L��������������һ�N��������ʽ�����������ں�����r�µ���I���䔵����Ҫ���Ǽ����RDBMSģ�͡����ó���M��������Ó�x��RDBMS�c��֮�g���������IJ���M����������ԭ���@�N�������܄������ε�RDBMS��ԃģ�ͣ����������ُ������҂������ᵽ�ĺ��ε�RDBMSģ�͡�
��ֱ���ɵĔ���ģ���Ը������ó����ض��ķ�ʽ�B�ӵ����������ϣ�ԓ��ʽʹ�ÿ͑��Pϵ��������I�YԴҎ����ӑB�����J�C�đ��ó����ܴ�̶��ڷ���ˮƽ������x���@�N���xֱ���漰���������A�Oʩ����ijЩ��r�£��@Щ���ó�����S�п���ֱ���L���惦/�������յ�SOA�M���������ṩ����yһ�Ĕ��������Ժ�����������������������SOA�M�����������N������ϵ�y���Ԕ������ض��ķ�ʽ���г�Ҋ���΄գ���ȥ�غ������ԙz�顣�@�N�����������m�����z�����ú͔����Y��,
�����چ��������L��ʽ�ϕ��Ɖ�SOA������ԭ�t��Ҳ���ܮa������������һ���Ԇ��}�� ���ߌ��I�W���
SOA��ˮƽ����ģ��
���o�Ɇ�ˮƽģ������SOAԭ�t����������ص؏�SOA�M���г�����˔������ա����^������ʹ����Ч���б�Ҫ�����Pϵ�͔������M�г����x��̎����Ч���c�������P�����̡���SOA�ܘ���֪������С�ĵı����������t�@�����ɞ鲻����Խ���ϵK��
ˮƽ��SOA���������ѽ��_ʼ�������m�ô��ij�������Q�@�����}�Ҋ�ķ�����MapReduce�����ԑ�����Hadoop��ʽ���Ƙ��ܡ�Hadoop�Լ���Ƶķ������Էְl���������L��������Ȼ���в�ԃ�@һ�ֲ�ʽ��Ϣ�����P�Y�������H�ϣ�SOA�M������MapReduce����Ɣ���������������һ�N��ԃ���ܑ��á�
Ч�ʆ��}
Ч�ʆ��}�^����s�����ˮƽ������ģ�Ϳ�����ͨ�^��ƴ����SOA���̵���Ϣ���տ�������ɵģ�һ����Ҫ�IJ��E��Ҫ�_���cԓ�������P���_�N�~�ȱ�������ͳ̶ȡ��@���Ԏ����p���cSOA���P�Ĕ����L���_�N���������ܿ˷��惦ϵ�y�����Ć��}������@Щ�惦ϵ�y�ѽ�ͨ�^ˮƽģ��Ó�x��SOA�M���������ױ������c���t�͔�����ݔ�����P�Ć��}���e�أ�������������Ʒֲ��ģ���ôʹ�������͕��a����׃�ľW�j���t��
�������}��һ����Q�����ǬF���Ӵ惦ģʽ�������첻�ǴűP������һ�M��B�ӵĸ��پ����c����惦�ڱ��ȴ��У�Ҳ�����D��̑BӲ�P��Ȼ���شűP������ƴ惦�������㷨̎���@Щ�����c֮�g�Ļ�ӣ��Ķ���ƽ��惦�ɱ���ͬ�rҲ��ƽ��ͬ���ظ��³ɱ��������ܡ�
���ڴ�����Ҳ�ǽ������Ԅ����m���ڴ���������ąR������������һ��Ӌ�㲻ͬ���c܇�v�����Ľ�ͨ�b�y���á��@�N�������Ԯa�������Ĕ�������������R���������һ���߀�惦�ڃȴ��У����һС�r�惦���W���У����һ����ڴűP�ϣ���ô���Ƒ��ó�������Č��H�r�g����ͨ�^�����L���YԴ�õ��M��,Ȼ�����O�����r�҂�����ʹ��һЩ�����ˡ������đ��ó����Ǖ����ӡ�
SOA���dz���ģ����������[���˵�Ӱ����ܺ�푑��r�g�ď��s�ԕr���@�N�����Σ�U�̶ȕ���ߡ������L��Ҳ���@�ӵģ����,SOA�ܘ�����Ҫ�J��ؿ��]�����c����֮�g��ƽ���Pϵ���������ض��ĘI����������
Hadoop
Hadoopּ��ͨ�^һ���߶ȿɔUչ�ķֲ�ʽ����̎��ϵ�y�������͔������M�В��裬�Ԯa����Y����Hadoop�Ŀ���������֣��քe��Hadoop
Distributed File System��HDFS����HadoopMapReduce����ģ�ͣ��Լ�Hadoop Common��
Hadoopƽ�_���ڲ����dz����͵Ĕ��������Կ����f��һ������Ĺ��ߡ����˳���Hadoop����ģ�͵�һЩ���s�ԣ��ѽ����F�˶�����Hadoop֮���\�еđ����_�l�Z�ԡ�Pig��Hive��Jaql�����еĴ�����������Java�⣬��߀�܉��������Z�Ծ���map��reduce��������ʹ�÷Q��Hadoop
Streaming��������Streaming����API�{���������c����������
�����x
�ļ��g�Ƕȶ��ԣ�����ͨ�^߅���B�ӵĹ��c�D���D�е�ÿ�����c���ǡ��\��������m�����������܉���ij�N�̶���̎�����ȵĔ��������c���Բ�����ݔ���ݔ����Ҳ����������ݔ���ݔ����һ�����c��ݔ���c����һ����������c��ݔ����B�ӡ��D�ε�߅�����@Щ���c�o��ϵ��һ�𣬱�ʾ���\���֮�g�ƄӵĔ�������
����Apache Hadoop���_Դ�Ŀ��ͨ�^��������RFID���罻ý�w����������ӛ䛺�������Դ�ṩ�����͔�������rֵ��
Streams
����IBM InfoSphere Streams����IBMInfoSphere
Streams�����QStreams���У������������^�������ٿؔ�������ÿ��犿��ܰ��������f���¼������\�����Ȼ���@Щ�������ЄӑB�������@헷������|�l�����¼���ʹ��I���ü��r�����܌��r��ȡ�Єӣ���K���ƘI�ճɹ���
���������^�@Щ�����M����Streams���ṩ�\����������惦������λ�ã�����������^�ӑB����ijЩ������ҕ����o�rֵ���t���G���@Щ����������ܕ��J��Streams�c���s�¼�̎����CEP��
ϵ�y�����ƣ����^Streams���OӋ�ɔUչ�Ը��ߣ�����֧�ֵĔ�������Ҳ������ϵ�y��öࡣ���⣬Streams߀�߂���ߵ���I�����ԣ������߿����ԡ��S���đ��ó����_�l���߰����{�ȡ�
�����@�ӵ�Ŀ�ģ��S��M���_ʼ�����Լ��Ĵ�����Ӌ�������^��������ָ�����ƶ����ԁ�f�{�����ܲ��T��Ŀ�ˣ��Ķ����������o�����ô�����������һ���I�Y�a��
13 ����Ӌ��
������Ӌ��Ҳ��Ҫ�Pע�c������Ϣ����Ӌ����ƵĆ��}���@ЩӋ����횽�Q�����}��
��Ԫ��������������Ҫ�����ɿ���Ԫ������������F���������磬һ����I�؏�ُ�I����ͬ�Ĕ������ɴΣ���ԭ��H�H��ԓ�������ڃɂ���ͬ�Ĵ惦���ʹ���˲�ͬ�����Q��
���[˽����I��Ҫ�����Pע�����[˽����Ć��}�����������罻ý�w�M�Д���������
�������|�������]�������������ͳ����ٶȣ��M����Ҫ�_���ķN���e�Ĕ����|�����ڡ����á����|����
����Ϣ�������ڹ�����������Ӌ����Ҫ�ƶ���n���ԣ��_���惦�ɱ������������ơ�����֮�⣬�M����Ҫ�O������Ӌ�����Ա㰴�շ�ҎҪ�����̎�Ô�����
�������ˆT����K����I��Ҫ��ļ������T�����磬ʯ���c��Ȼ�˾�ȵĿ�̽�_�ɲ��T�Ĺ���Tؓ؟�����������������PԪ�����ڃȡ��@Щ����T��Ҫ����M����һ�µ�����Ҏ��������ُ�I�ѽ����е��ⲿ����������֮�⣬�罻ý�w����T��Ҫ�c������������ˆT��Ϲ������ƶ����P�ɽ��ܵ���Ϣʹ�÷����IJ��ԡ�
14 ���P���}
���ڴ��Ĵ惦���}�������}���ɺ�ҕ��
�������}
�@�����f�ġ���������ͨ�����_��PB���Ĕ���Ҏģ����ˣ����������惦ϵ�yҲһ��Ҫ�������ȼ��ĔUչ�������c��ͬ�r���惦ϵ�y�ĔUչһ��Ҫ���㣬����ͨ�^����ģ�K��űP���������������������Ҫͣ�C���ڽ�Q�������}�ϣ����ò���LSI��˾��ȫ��Nytro™���ܻ��W���Q����������Nytro�aƷ���͑����Ԍ���������̎���������30�������ҳ��^ÿ��4.0GB1�ij��m�����������dz��m���ڴ�������
���t���}
����������߀���ڌ��r�ԵĆ��}���e���漰���c�W�Ͻ����߽�������P�đ��á��кܶࡰ�������íh����Ҫ�^�ߵ�IOPS���ܣ�����HPC������Ӌ�㡣���⣬������̓�M�����ռ�Ҳ�����ˌ���IOPS��������������׃�˂��yIT�h��һ�ӡ�����ӭ���@Щ���𣬸��Nģʽ�Ĺ̑B�惦�O�䑪�\������С�����ε��ڷ������Ȳ������پ��棬��ȫ�̑B���|�ɔUչ�惦ϵ�yͨ�^�������W��惦���Ԅӡ����ܵ،����c�����M���x/�����پ����LSI
Nytroϵ�ЮaƷ�ȵȶ�����lչ��
��ȫ���}
ijЩ�����ИI�đ��ã�������ڔ������t����Ϣ�Լ��������ȶ����Լ��İ�ȫ�˜ʺͱ����������mȻ����IT�����߁��f�@Щ���]��ʲô��ͬ�����Ҷ��DZ����ĵģ����ǣ�������������Ҫ�����������������^ȥ���������@�N��������L������r�������ô�����һЩ�µġ���Ҫ���]�İ�ȫ�Ԇ��}���@�ͳ���w�F�����û���DuraClass™
���g��LSI SandForce®�W��̎�����ă����ˣ����F����I���W�����ܺͿɿ��ԣ����F���Ρ����đ��ü��٣��Ȱ�ȫ�ַ��㡣
�ɱ����}
������Щ����ʹ�ô��h������I���f���ɱ��������P�I�Ć��}������Ƴɱ�������ζ���҂�Ҫÿһ�_�O�䶼���F���ߵġ�Ч�ʡ���ͬ�r߀Ҫ�p����Щ���F�IJ������؏͔����h���ȼ��g�ѽ��M�뵽���惦�Ј�������߀����̎������Ĕ�����ͣ��@�����Ԟ���惦���Î�������ărֵ�������惦Ч�ʡ��ڔ������������L�ĭh���У�ͨ�^�p�ٺ�˴惦�����ģ�����ֻ�ǽ��ׂ͎��ٷ��c���@�N�O㏱��^�ķ�����Ҳֻ��LSI�Ƴ���Syncro™
MX-B�C�ܷ��������ӱP�O�䶼�܉�@�����@��Ͷ�Y�؈���������ʹ�õĂ��y�����������H�����ʸߣ����Ҿ����^�ߵľS���Q�ɱ������������Q�������ĵĪ��������������������t�܌��ɿ����������_100�������Ҍ����Cϵ�y�����ģ��ܞ�ÿһ�����ӷ������ṩΨһ�������R�ɺ���ϵ�y�����������ɿ��ԣ����ҹ���ʸ��_60%�����������˹�ʡ�ɱ��Ć��}��
�����ķe��
�S������ö����漰����Ҏ��Ć��}���@Щ��Ҏͨ��Ҫ��Ҫ���������ߎ�ʮ�ꡣ�����t����Ϣͨ���Ǟ��˱��C���ߵ�������ȫ����ؔ����Ϣͨ��Ҫ����7�ꡣ����Щʹ�ô��惦���Ñ�sϣ�������܉���L�ĕr�g������κΔ������ǚvʷӛ䛵�һ���֣����Ҕ����ķ������ǻ��ڕr�g���M�еġ�Ҫ���F�L�ڵĔ������棬��Ҫ��惦�S���_�l���܉���m�M�Д���һ���ԙz�y�Ĺ����Լ��������C�L�ڸ߿��õ����ԡ�ͬ�r߀Ҫ���F����ֱ����ԭλ���µĹ�������
�`����
���惦ϵ�y�Ļ��A�OʩҎģͨ�����ܴ���˱�횽��^�м��OӋ�����ܱ��C�惦ϵ�y���`���ԣ�ʹ���܉��S�����÷���ܛ��һ��U�ݼ��Uչ���ڴ��惦�h���У��ѽ��]�б�Ҫ���������w���ˣ���锵����ͬ�r�����ڶ�������վ�c��һ�����͵Ĕ����惦���A�Oʩһ���_ʼͶ��ʹ�ã��ͺ��y���{���ˣ����������܉��m�����N��ͬ�đ�����ͺ͔���������
���ø�֪
����һ��ʹ�ô����Ñ��ѽ��_�l����һЩᘌ����õĶ��ƵĻ��A�Oʩ������ᘌ������Ŀ�_�l��ϵ�y��߀�д��ͻ��W�����̄���Č��÷������ȡ��������惦ϵ�y�I���ø�֪���g��ʹ��Խ��Խ�ձ飬��Ҳ�Ǹ���ϵ�yЧ�ʺ����ܵ���Ҫ�ֶΣ����ԣ����ø�֪���gҲ��ԓ���ڴ��惦�h���
ᘌ�С�Ñ�
��ه���IJ��H�H����Щ����Ĵ����Ñ�Ⱥ�w������һ�N�̘I����С����Iδ��Ҳһ�������õ������҂���������Щ�惦�S���ѽ����_�lһЩС�͵ġ������惦ϵ�y����Ҫ������Щ���ɱ����^���е��Ñ���
15 �lչǰ��
�������x������������ռ��ľW�j�О��������ģ��ܵ����P���T����I�ɼ��ģ��N���������a���挍��D��ϲ�õģ��ǂ��y�Y�������x�Ĕ��� ��
2013��5��10�գ�����Ͱͼ��F���¾���ϯ�R�����Ԍ�ʮ��������ϣ���ж�ΰ��O�FCEO��λ�������������ж��ǰ�����v���R���f�����߀�]����PC�r���ĕr���Ƅӻ��W���ˣ�߀�]�����Ƅӻ��W�ĕr���r������
�������r���ğᳱ��ܛ��˾���a��һ����ӵ�ܛ������Ҫ�Ǟ鹤�̽��O���s�YԴ���Ч�ʡ����@���^������Ԟ����繝�s40%����Դ�����_�@��ܛ����ǰ����������ܛ�F��������о��_ʼ�����Կ�������Ŀ�˲��H�Ǟ��˹��s����Դ�������Pע���ܻ��\�I��ͨ�^��ۙȡů�������{���L���Լ�����ȷe�����ij���������������ζŽ^��Դ���M�����o���ṩһЩ�������Ҿ�����һЩ��׃������o���ṩ���Д������Ҿ����������硣��ܛʷ��˹�@���f�������ܽ����������ĈFꠌ�ע�����顣
�ĺ��������С��ἃ�������õ���Ϣ���@���W�j�ܘ��͔���̎����������Ҳ�Ǿ�������ڽ��v�ˎ�������С��|�ɡ�ӑՓ������֮���K��ӭ���ˌ������ĕr����2012��3��22�գ��W���R��������Ͷ�Y2�|��Ԫ���Ӵ����P�a�I�lչ�����������ԡ���������ґ��ԡ��W���R���������������x�顰δ������ʯ�͡���
���P���ɣ�
��һ����c���������Ĵ惦��̎�����P�Ĺ�˾�����������Ϣ���ؠ�˼�������ؿơ���̩���ա����ܺ��š�
�ڶ�����c�������Ľ��O�c�\�I�S�o���P�Ĺ�˾�������s֮����^�Ƽ����y�ſƼ���
��������cҕ�l���������P�Ĺ�˾������ҕ�l�O�ؘI�՞����ĺ�����ҕ�����A�ɷݡ������ɷݡ��Aƽ�ɷݡ�
��������c���ܻ����˙C�����������P�Ĺ�˾���Pע�ƴ�Ӎ�w������ܛ�����|�����ŵȡ�
�rֵ
��
�ȸ�������Facebook�����Ӻ�����Ϣʹ���˂����О����w�ļ������y���ɞ���ܡ��ھ��Ñ����О����T��ϲ�ã���y�����Ĕ��������ҵ��������Ñ��dȤ�����T�ĮaƷ�ͷ��գ������aƷ�ͷ����M��ᘌ��Ե��{���̓������@���Ǵ��ărֵ����Ҳ�����@�F���������ИI�����M����
���r�����R�����ɔ����S���țQ���ġ��罻�W�j�d�𣬴�����UGC(���W�g�Z��ȫ�Q��User Generated
Content�����Ñ����Ƀ��ݵ���˼)���ݡ����l���ı���Ϣ��ҕ�l���DƬ�ȷǽY�����������F�ˡ����⣬���W�Ĕ������������Ƅӻ��W�ܸ��ʴ_��������ռ��Ñ���Ϣ������λ�á�������Ϣ�Ȕ������Ĕ��������f�����M����r������Ӳ�����@�Ѹ����ϔ����lչ���_����
������ͨ���Á�����һ����˾����Ĵ����ǽY�����Ͱ�Y�������������ἰ��������ͨ����ָ��Q���}��һ�N�������������M�з����ھ��M�����Ы@���Ѓrֵ��Ϣ����K�ܻ���һ�N�µ��̘Iģʽ��
�mȻ���ڇ���߀̎�ڳ����A�Σ������̘I�rֵ�ѽ��@�F���������ȣ��������Д����Ĺ�˾վ�ڽ�V�ϣ����ڔ��������ɮa���ܺõ�Ч�棻��Σ����ڔ����ھ���кܶ��̘Iģʽ�Q������λ�ǶȲ�ͬ������ؔ����������������I���Ȳ������ھ������������I�������ҵ��Ñ������͠I�N�ɱ��������I�N���ʣ�����������
δ�����������ܳɞ����Ľ�����Ʒ�����������������Ǵ������������ǔ����������Nࡢ�ǘ˜ʻ������ărֵ�����ˣ����ărֵ��ͨ�^����������������ú�@ȡ���Ĕ����rֵ������������δ������������A�Oʩһ�ӣ��Д����ṩ���������ߡ��O���ߣ������Ľ�����Ì���׃��һ��a�I�����yӋ�������γɵ��Ј�Ҏģ��51�|��Ԫ���ң�����2017�꣬�˔����AӋ���ϝq��530�|��Ԫ��
�惦
���@��һ������������Ĕ����YԴʹ�ø����I���_ʼ�������M�̣��oՓ�W�g�硢�̽�߀�������������I���_ʼ�@�N�M�̡��������������W����W���ڼ����.
�S�������õı��l�����L�����ѽ����������Լ����صļܘ�������Ҳֱ���Ƅ��˴惦���W�j�Լ�Ӌ�㼼�g�İlչ������̎�����@�N�����������һ���µ�����Ӳ���İlչ��K߀����ܛ�������Ƅӵģ��҂������@�Ŀ���������������������Ӱ��������惦���A�Oʩ�İlչ������һ���濴���@һ׃�����惦�S�̺�����IT���A�Oʩ�S��δ�L����һ���C�����S���Y���������ͷǽY�����������ij��m���L���Լ�����������Դ�Ķ��ӻ�����ǰ�惦ϵ�y���OӋ�ѽ��o���M������õ���Ҫ���惦�S���ѽ����R���@һ�c�������_ʼ�Ļ��ډK���ļ��Ĵ惦ϵ�y�ļܘ��OӋ���m���@Щ�µ�Ҫ��
ᘌ����������I��Ʒ�ƴ惦��I�У�IBM��EMC��LSISandForce ��
�Ƅ��惦��INTEL�����ա����������ġ�������ِ�T�F�˵�
16 �̘Iģʽ
���ȾW�j�V��Ͷ�����Ă��y������Ⱥ�w�ĠI�N�D���Ի��I�N��������ُ�I�D����Ⱥُ�I���mȻ�Ј���h�����ã����Ǿ߂䔵���ھ������Ĺ�˾�s�����Y����A��
163����һ���ܺõ�ҕ�Ǻ��ߡ����Y���Ƕȁ�����ʲô�ӵĹ�˾�Ѓrֵ��ʲô�ӵĹ�˾�]�Ѓrֵ��������еĔ���Ҏģ�������Ļ��Ժ��@�ҹ�˾���\�á���ጔ������������Ϳ��Կ����@�ҹ�˾�ĺ��ĸ����������@�ׂ����������Y���Pע���c��
�Ƅӻ��W�c�罻�W�j�d�����������µ����̣����W�I�N�����О�����Ļ��A�����Ի��r���^�ɡ����I��˾���á��������V�V����ʲô�����_�ĕr�g���l�����_���Ñ���ʲô�Ǒ�ԓ�l�������_���ݵȣ��@���������ˏV���̵�����
�罻�W�j�a���˺����Ñ��Լ����r�������Ĕ�����ͬ�r�罻�W�jҲӛ����Ñ�Ⱥ�w����w��ͨ�^�����ھ��@Щ�������˽��Ñ���Ȼ���@Щ������Ĕ�����Ϣ�ƽo��Ҫ��Ʒ���̼һ������I�N��˾��
���H�ϣ����Ñ�Ⱥ���ʼ��֣�ֱ���ҵ�Ҫ�ҵ��Ñ������罻���ݱ����ھ��������ĽY������ͨ�^���N�㷨���F�Ĕ�����Ϣ���ף����Ǐ��ĺƞ��Լ����罻�����ھ�˾�OӋ��ӯ��ģʽ���@�҃H�H�������˵�С��˾�õ�����ʹͶ�Y��δ�����Ј�����������˞����ģ�����ӭ���Ñ�����ǰ�����Ҫ�ҵ��@������Ⱥ��
���Ƅӻ��W�I��˾���_�l�߽Ƕ��ҵ������ھ�ķ���ͨ�^�ṩ���M�ļ��g���գ������_�l���˽⑪�à�r��
17 ��I����
���ȵ���I���������^����һ������Ҫ�����Ծ����˿ڻ����ą^�e���Ї����MȺ�w���a�����@�N���������c������Ȳ���ͬ�ն��Z��
���S�����N�S���O�䡢���W����Ӌ���ƴ惦�ȼ��g�İlչ���˺��������܉�E�����Ա�ӛ䛡����Ƅӻ��W�ĺ��ľW�j���c���ˣ������ǾW퓡�������ը�£������ھ��@Щ������Ҳ���R�����g�c�̘I���p������
���ȣ���Ό�������Ϣ�c�aƷ������Y�ϣ��_���aƷ����Ճ����Ǵ��̘Iģʽ��չ�ϵ�����֮һ��
��Σ��ɋD�y��o��֮���������P�I߀�������l�ȓ��Д�����
���Ј��Ƕȁ�������߀���R�������ص�����
�a�I�猦�ڴ��ğ�����m���ص�ͬ�r���Y��Ҳ���J�ذl�F���@һڅ�ݣ����_ʼ�Pע�����ھ�ͷ����˾�����ڴˣ����Ї����I��ӛ�ߌ��L�ˌ��@���I�������о����Y����ʿ��
���Ї����I����Խ��Խ�౻�ἰ�����X�Ô����ھ����̘Iģʽ����ʲô�µ�څ�ݣ�
�𣺴����nj��r������̎���͌��r�Y���Č���Խ��Խ��Ĕ����ھ�ǰ�˻��������fֱ�Ӟ����M�߸�֪��ֱ���ṩ���M������Ҫ�ķ��գ�ͨ����ʽ���Q���˸��N���ӵĂ��Ի����]�ķ��ա�
���Ї����I���ڴ������£����ڸ��N�������ھ�Ĺ�˾��ʲô�µęC����
�𣺴���ǰ���ǔ���������Ѹ�������Լ����������������ӣ�ǰ���������Ñ����О����֙C����X��Խ��Խ�࣬�T��Խ��Խ�ͣ�����һ�������������Nƽ�_���_�Ō������������ӣ����σɂ����ص��Q�����ܴ��������ֱ�Ӟ����M�߷��յĴ���˾���Ա����ٷ��c��Ϣ�Ƽ�����˾(���º��Q���ٷ��c��)�������@�ҹ�˾�ķ����ú��Q���r�g��ǡ�÷������@�ӵ�څ�ݡ�
���Ї����I����Ͷ�Y�Ƕȣ�����ô�������ھ��˾��Ͷ�Y�rֵ��˾ǰ����
���ҿ����Դ�����l�c���̘Iģʽ����̵ĺ��m���ծaƷ��������ǰ�������Ƿ���څ�ݵģ����Ǿ��w�aƷ�͔���̎����������������K�ɔ������ء�
���Ї����I�����ИI�Ƕȿ��������T��������������ھ���Ҫ�߂���Щ��Ҫ�����أ�
���T����Ҫ����Ϋ@�ô����������������|�������P���Լ��Ƿ��кõ�̎�������ͼ��g����K���õķ������̘I�����P�I��
���Ї����I�����㿴����IDGͶ�Y�ٷ��c��Ҫ�����Ďׂ��P�I�c�����J��ٷ��c��̎�ĸ����h����Σ�
�𣺰ٷ��c�������õĈFꠡ����g�������ИI�����Լ��о��������������Ą�ʼ��֮�g���л��a����ͻ�������⣬�������Q���Ͱlչ�����˴��څ�ݣ�������������һ�c�I�ȡ������h����Ҫȡ�Q�ڇ��Ȼ��W��˾�������Ǵ�˾�����_�Ŕ����đB�Ⱥ��ٶȣ�ͬ�rҲ���������ļ��g�����ͮaƷ�Ƿ��܉�س�Խ�Ñ�������
��������������r���ѽ������ęC����ȫ��֪����ԃ��˾�����a�������a���о������ָ���������ѽ��B��ÿһ���ИI�͘I�����I����u�ɞ���Ҫ�����a���أ����˂����ں����������\�Ì��Aʾ����һ�����a�����L�����M��ӯ���˳��ĵ�����
�������a�Ĉ��l����Ѹ�ٳɞ���Ӌ��C�ИI�������b�ğ��T���Ҳ�����˽��ڽ�ĸ߶��Pע�����S�����W���g�IJ���lչ�������������Y�a���@һ�c�ژI���ѽ��γɹ��R��������f��Ӌ��锵���Y�a�ṩ�˱��ܡ��L���Ĉ�������������ô��αP����Y�a��ʹ��������������I�Q����������������գ��t�Ǵ��ĺ����h�}��Ҳ����Ӌ����ڵ��`��ͱ�Ȼ����������
���ϣ�ȫ���W���^�������R���ˡ������r������������Ҫ���x������EMC������(��)��IBM��ܛ(��)�ڃȵ�ȫ��IT
���^����ͨ�^��ُ���������P�S�́팍�F���g���ϣ����Ҋ�䌦����������ҕ�� ���ߌ��I�W���
����������һ���^�µĸ��Ŀǰ��δֱ���Ԍ������~���҇�����������o������֧�֡����^����2011��12��8�չ��Ų��l�������W��ʮ���塱Ҏ���ϣ�����Ϣ̎�����g����4��P�I���g���¹���֮һ������������а����˺��������惦�������ھD��ҕ�l���ܷ������@���Ǵ�����Ҫ�M�ɲ��֡�������3��P�I���g���¹��̣�������Ϣ��֪���g����Ϣ��ݔ���g����Ϣ��ȫ���g��Ҳ���c�������������P��
18 Ͷ�Y���c
���������^��Ӌ�㡢���W֮��IT�a�I��һ����Եļ��g׃���Ӌ����Ҫ�锵���Y�a�ṩ�˱��ܡ��L���Ĉ��������������������������Ѓrֵ���Y�a����I�Ȳ��Ľ��I������Ϣ�����W�����е���Ʒ������Ϣ�����W�����е����c�˽�����Ϣ��λ����Ϣ�ȣ��䔵�����h�h��Խ�F����IIT�ܘ��ͻ��A�Oʩ�ij��d���������r��Ҫ��Ҳ�����Խ�F�е�Ӌ����������αP���@Щ�����Y�a��ʹ��������������I�Q����������������գ��Ǵ��ĺ����h�}��Ҳ����Ӌ����ڵ��`��ͱ�Ȼ����������
�������r���W������M�ߵĽ���������������I�Ľ���׃��ģ���������ɞ���ĵ��Y�a���������Ӱ���I�ĘI��ģʽ�������ؘ����Ļ��ͽM������ˣ�������������ģʽ������I�ěQ�ߡ��M���͘I�����̡����������ʽ�����a�����Ӱ푡�����������ô������N�����M�ߡ������������Ч������Ϣ�������A�У����Ђ��y�ĮaƷ��˾��ֻ�ܜS�������Ñ�ƽ�_����˾�ĸ�ӹ����˥�䲻�ǹ�����Ť�D�ġ�
������ˣ����r�������l��һ݆��Ϣ��Ͷ�Y�ͽ��O�ᳱ����IDC�A�y����2020��ȫ��������35ZB�Ĕ��������������a�t�A�yδ�����aƷ�������ИI�đ��þ͌��a��7ǧ�|��Ԫ�ĝ����Ј���δ���Ї����aƷ�ĝ����Ј�Ҏģ�����_��1.57�f�|Ԫ���oIT�ИI�_����һ���µ��S��r����
������ǰ�҂�߀̎�ڴ��r����ǰҹ���AӋ�������ꌢ�Ǵ��Ј��������ڣ�2014���Ժ���aƷ�����γɘI���� |